Couplé options de compilation agressives
Test du couplé en utilisant les options de compilation "agressives"
CURIE
On teste les options
-O3 -axAVX,SSE4.2 -fp-model fast=2
du compilateur fortran sur curie avec la config IPSLCM6.0.7-LR r3078
Mise en place:
Inclusion des options dans les différents Makefile:
- util/AA_make.gdef
remplacer:
#-Q- curie F_O = -DCPP_PARA -O3 $(F_D) $(F_P) -I$(MODDIR) -module $(MODDIR) -fp-model precise
par
#-Q- curie F_O = -DCPP_PARA -O3 -axAVX,SSE4.2 $(F_D) $(F_P) -I$(MODDIR) -module $(MODDIR) -fp-model fast=2
- oasis3-mct/util/make_dir/make.bullx.curie*
remplacer
F90FLAGS_1 = -O2 -xAVX -I.
par
F90FLAGS_1 = -O3 -axAVX,SSE4.2 -fp-model fast=2 -I.
- modeles/LMDZ/arch/arch-X64_CURIE.fcm
remplacer
%BASE_FFLAGS -i4 -r8 -auto -align all -I$(MKL_INC_DIR) -I$(MKL_INC_DIR)/intel64/lp64 -fp-model strict %PROD_FFLAGS -O2
par
%BASE_FFLAGS -i4 -r8 -auto -align all -I$(MKL_INC_DIR) -I$(MKL_INC_DIR)/intel64/lp64 -fp-model fast=2 %PROD_FFLAGS -O3 -axAVX,SSE4.2
- modeles/ORCHIDEE/arch/arch-X64_CURIE.fcm
remplacer
%BASE_FFLAGS -i4 -r8 -auto -align all -fp-model precise %PROD_FFLAGS -O3
par
%BASE_FFLAGS -i4 -r8 -auto -align all -fp-model fast=2 %PROD_FFLAGS -O3 -axAVX,SSE4.2
- modeles/NEMOGCM/ARCH/arch-X64_CURIE.fcm
remplacer
%FCFLAGS -i4 -r8 -O3 -fp-model precise
par
%FCFLAGS -i4 -r8 -O3 -axAVX,SSE4.2 -fp-model fast=2
- config/IPSLCM6/SOURCES/NEMO/arch-X64_CURIE.fcm:
remplacer
%FCFLAGS -i4 -r8 -O3 -fp-model precise
par
%FCFLAGS -i4 -r8 -O3 -axAVX,SSE4.2 -fp-model fast=2
- modeles/XIOS/arch/arch-X64_CURIE.fcm (peut-être pas nécessaire)
remplacer
%PROD_FFLAGS -O3
par
%PROD_FFLAGS -O3 -axAVX,SSE4.2 -fp-model fast=2
Tests avec fortran/intel/14.0.3.174
C'est la version par défaut du compilateur au 06/01/2017
Installation dans: /ccc/cont003/home/gencmip6/p86fair/IPSLCM6.0.7-LR.testcompil/modipsl.14.03/
Lancement de 10 ans de CM607-LR-pdCtrl-opt14
temps d'exécution par an:
| real CPU / an | elapsed / an |
| 9714 | 2h42m |
Pour CM607-LR-pdCtrl-01cont, on a avec le même environnement:
| real CPU / an | elapsed / an |
| 10620 | 2h58m |
Tests avec fortran/intel/16.0.3.210
Installation dans: /ccc/cont003/home/gencmip6/p86fair/IPSLCM6.0.7-LR.testcompil/modipsl.16.0.3
Charger le nouveau environnement intel pour la compilation et l'exécution (à modifier quelque part dans libIGCM_sys/libIGCM_sys_curie.ksh et .atlas_env_netcdf4.3.3.1_hdf5_parallel_curie_ksh) :
module unload nco/4.4.8 module unload netcdf/4.3.3.1_hdf5_parallel module unload intel/14.0.3.174 module load intel/16.0.3.210 module load netcdf/4.3.3.1_hdf5_parallel
temps d'exécution par an:
| real CPU / an | elapsed / an |
| 9569 | 2h40m |
L'équilibrage donné par lucia
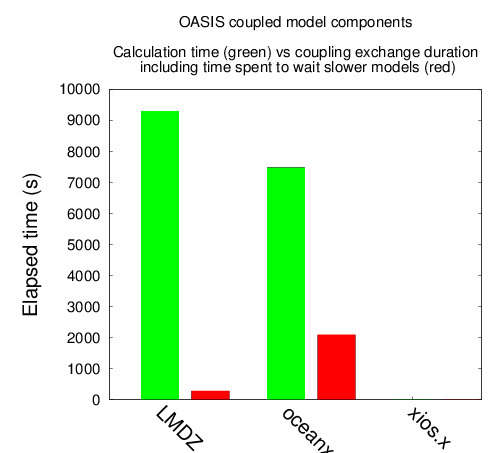{kind=link}
Tests avec fortran/intel/17.0.2.174 (juin 2017)
On reprend les tests à partir du modèle IPSLCM6.0.10-LR en faisant tourner le couplé complet 20 à 30 ans. On lance 3 simulations (répertoire de base /ccc/cont003/home/gencmip6/p86fair/IPSLCM6.0.10-LRtestcompil) :
- une dans l'environnement intel/14.0.3.174 avec les options de compilations habituelles (répertoire .../modipsl.14.0.3): CM6010-LR-pdCtrl-ref
- une dans l'environnement intel/17.0.2.174 avec les options de compilations habituelles (répertoire .../modipsl.17.0.2): CM6010-LR-pdCtrl-ref-c17
- une dans l'environnement intel/17.0.2.174 avec les options de compilations agressives(répertoire .../modipsl.17.0.2.optiim): CM6010-LR-pdCtrl-opt-c17
Pour charger l'environnement intel 17.0.2 pour la compilation et l'exécution, il y a besoin de faire:
module unload python/2.7.8 module unload nco/4.4.8 module unload netcdf/4.3.3.1_hdf5_parallel module unload intel/14.0.3.174 module unload c/intel/14.0.3.174 module unload c++/intel/14.0.3.174 module unload fortran/intel/14.0.3.174 module unload mkl/17.0.2.174 module load intel/17.0.2.174 module load c++/intel/17.0.2.174 module load fortran/intel/17.0.2.174 module load c/intel/17.0.2.174 module load netcdf/4.3.3.1_hdf5_parallel module load nco module load cdo/1.6.7_netcdf-4.3.2_hdf5
Du coup, j'ai modifié libIGCM/libIGCM_sys/libIGCM_sys_curie.ksh:
===================================================================
--- libIGCM/libIGCM_sys/libIGCM_sys_curie.ksh (revision 1390)
+++ libIGCM/libIGCM_sys/libIGCM_sys_curie.ksh (working copy)
@@ -93,13 +93,15 @@
#====================================================
if [ X${TaskType} = Xcomputing ] ; then
module load python/2.7.8 > /dev/null 2>&1
- . /ccc/cont003/home/dsm/p86ipsl/.atlas_env_netcdf4.3.3.1_hdf5_parallel_curie_ksh > /dev/null 2>&1
+# . /ccc/cont003/home/dsm/p86ipsl/.atlas_env_netcdf4.3.3.1_hdf5_parallel_curie_ksh > /dev/null 2>&1
+ . /ccc/cont003/home/gencmip6/p86fair/IPSLCM6.0.10-LRtestcompil/modipsl.17.0.2/atlas_env_netcdf4.3.3.1_hdf5_parallel_curie_ksh
# to run with netcdf 3.6.3 ie compilation done before 17/2/2014
# uncomment 2 lines :
# module unload netcdf
# module load netcdf/3.6.3
else
- . /ccc/cont003/home/dsm/p86ipsl/.atlas_env_netcdf4.3.3.1_hdf5_parallel_curie_ksh > /dev/null 2>&1
+# . /ccc/cont003/home/dsm/p86ipsl/.atlas_env_netcdf4.3.3.1_hdf5_parallel_curie_ksh > /dev/null 2>&1
+ . /ccc/cont003/home/gencmip6/p86fair/IPSLCM6.0.10-LRtestcompil/modipsl.17.0.2/atlas_env_netcdf4.3.3.1_hdf5_parallel_curie_ksh > /dev/null 2>&1
export PCMDI_MP=/ccc/work/cont003/igcmg/igcmg/PCMDI-MP
avec les modifications suivantes dans IPSLCM6.0.10-LRtestcompil/modipsl.17.0.2/atlas_env_netcdf4.3.3.1_hdf5_parallel_curie_ksh par rapport à p86ipsl/.atlas_env_netcdf4.3.3.1_hdf5_parallel_curie_ksh:
53,69d52 < module load imagemagick/6.7.4 < #module load nco/4.4.8 < # < < module unload python/2.7.8 < module unload nco/4.4.8 < module unload netcdf/4.3.3.1_hdf5_parallel < module unload intel/14.0.3.174 < module unload c/intel/14.0.3.174 < module unload c++/intel/14.0.3.174 < module unload fortran/intel/14.0.3.174 < module unload mkl/17.0.2.174 < ##module unload mpi/bullxmpi/1.2.8.4 < module load intel/17.0.2.174 < module load c++/intel/17.0.2.174 < module load fortran/intel/17.0.2.174 < module load c/intel/17.0.2.174 71d53 < module load nco 73,74c55,56 < module load mkl/17.0.2.174 < #module load python/2.7.8 --- > module load imagemagick/6.7.4 > module load nco/4.4.8
Temps d'exécution par an:
CM6010-LR-pdCtrl-ref
| real CPU / an | elapsed / an |
| 6500s | 1h49m |
CM6010-LR-pdCtrl-ref-c17
| real CPU / an | elapsed / an |
| 6300s | 1h44m |
CM6010-LR-pdCtrl-opt-c17
| real CPU / an | elapsed / an |
| 5900s | 1h38m |
L'intermonitoring des 3 simulations
Conclusions:
Les simulations 14 et 17 standards se superposent exactement mais contrairement aux tests précédents effectués avec des versions du code du début de l'année et l'environnement intel/16.0.3.210 qui montraient des trajectoires différentes pour les variables issues d'ORCHIDEE, les trajectoires des modèles actuels ne semblent pas diverger quand on utilise les options de compilations "aggressives". L'utilisation de ces options permet de gagner 5 à 6% de temps elapsed sur le modèle couplé soit d'effectuer 15 ans de simulation couplé en une journée plutôt que 14.
ADA
On teste les options
-O3 -axAVX,SSE4.2 -fp-model fast=2
du compilateur fortran sur ada avec la config IPSLCM6.0.10-LR
Mise en place:
Inclusion des options dans les différents Makefile:
- util/AA_make.gdef
remplacer:
#-Q- ada F_O = -DCPP_PARA -shared-intel -mcmodel=large -O3 $(F_D) $(F_P) -I$(MODDIR) -module $(MODDIR) -fp-model precise
par
#-Q- ada F_O = -DCPP_PARA -shared-intel -mcmodel=large -O3 $(F_D) $(F_P) -I$(MODDIR) -module $(MODDIR) -axAVX,SSE4.2 -fp-model fast=2
- oasis3-mct/util/make_dir/make.bullx.curie*
remplacer
F90FLAGS_1 = -qsuffix=cpp=F90 $(COMFLAGS)
par
F90FLAGS_1 = -qsuffix=cpp=f90 $(COMFLAGS) -O3 -axAVX,SSE4.2 -fp-model fast=2
- modeles/LMDZ/arch/arch-X64_ADA.fcm
remplacer
%BASE_FFLAGS -integer-size 32 -real-size 64 -align all -shared-intel -mcmodel=large -fp-model precise %PROD_FFLAGS -O3
par
%BASE_FFLAGS -integer-size 32 -real-size 64 -align all -shared-intel -mcmodel=large -fp-model fast=2 %PROD_FFLAGS -O3 -axAVX,SSE4.2
- modeles/ORCHIDEE/arch/arch-X64_AD.fcm
remplacer
%BASE_FFLAGS -integer-size 32 -real-size 64 -align all -shared-intel -mcmodel=large -fp-model precise %PROD_FFLAGS -O3
par
%BASE_FFLAGS -integer-size 32 -real-size 64 -align all -shared-intel -mcmodel=large -fp-model fast=2 %PROD_FFLAGS -O3 -axAVX,SSE4.2
- modeles/NEMOGCM/ARCH/arch-X64_CURIE.fcm
remplacer
%FCFLAGS -DCPP_PARA -i4 -r8 -O3 -xAVX -fp-model precise
par
%FCFLAGS -DCPP_PARA -i4 -r8 -O3 -axAVX,SSE4.2 -fp-model fast=2
- config/IPSLCM6/SOURCES/NEMO/arch-X64_CURIE.fcm:
remplacer
%FCFLAGS -DCPP_PARA -i4 -r8 -O3 -xAVX -fp-model precise
par
%FCFLAGS -DCPP_PARA -i4 -r8 -O3 -axAVX,SSE4.2 -fp-model fast=2
- modeles/XIOS/arch/arch-X64_CURIE.fcm (peut-être pas nécessaire)
remplacer
%PROD_FFLAGS -O3
par
%PROD_FFLAGS -O3 -axAVX,SSE4.2 -fp-model fast=2
Pour l'exécution:
- utiliser l'environnement parallèle Intel pour ins_job (sinon le job demande trop de coeur et ne passe pas)
- modifier libIgcm/libIGCM_sys/libIGCM_sys_ada.ksh
+# module load intel/2016.2 > /dev/null 2>&1 + . /workgpfs/rech/gzi/rgzi004/IPSLCM6.0.10-LRtestcompil/intel_2017.2_std/atlas_env_ada_intel_2017_0_bash +# . /smphome/rech/psl/rpsl035/.atlas_env_ada_bash > /dev/null 2>&1
La différence entre atlas_env_ada_intel_2017_0_bash et /smphome/rech/psl/rpsl035/.atlas_env_ada_intel_2013_0_bash (par exemple) étant:
< #module unload intel >/dev/null 2>&1 < module unload intel < export LD_LIBRARY_PATH='' < module load intel/2017.2 --- > module unload intel >/dev/null 2>&1 > module load intel/2013.0 >/dev/null 2>&1
Temps d'exécution par an:
CM6010-LR-ada-2013
| real CPU / an | elapsed / an |
| 6000s | 1h38m |
CM6010-LR-ada-2017-std
| real CPU / an | elapsed / an |
| 5450s | 1h30m |
CM6010-LR-pdCtrl-opt-c17
pour l'instant plante
| real CPU / an | elapsed / an |